
Что такое дублированный контент?
Дублированный контент или просто дубли – это страницы на вашем сайте, которые полностью (четкие дубли) или частично (нечеткие дубли) совпадают друг с другом, но каждая из них имеет свой URL. Одна страница может иметь как один, так и несколько дублей.
Как появляется дублированный контент на сайте?
Как для четких, так и для нечетких дублей есть несколько причин возникновения. Четкие дубли могут возникнуть по следующим причинам:
- Они появляются из-за CMS сайта. Например, с помощью replytocom в WordPress, когда добавление новых комментариев создает автоматом и новые страницы, отличающиеся только URL.
- В результате ошибок веб-мастера.
- Из-за изменения структуры сайта. Например, при внедрении обновленного шаблона с новыми URL.
- Делаются владельцем сайта для определенных функций. Например, страницы с версиями текста для печати.
Нечеткие дубли на вашем сайте могут появиться по следующим причинам:
- Если есть частичное повторение одинакового текста на разных страницах сайта.
На примере показан анализ текста с главной страницы сайта в программе проверки уникальности «Text.ru». На картинке видно, с какими еще страницами этого же сайта и на сколько процентов он совпадает:
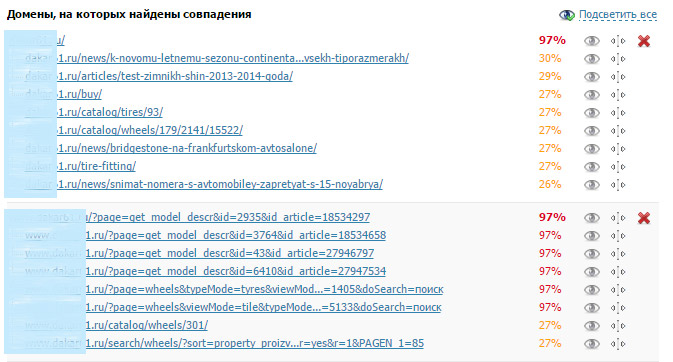
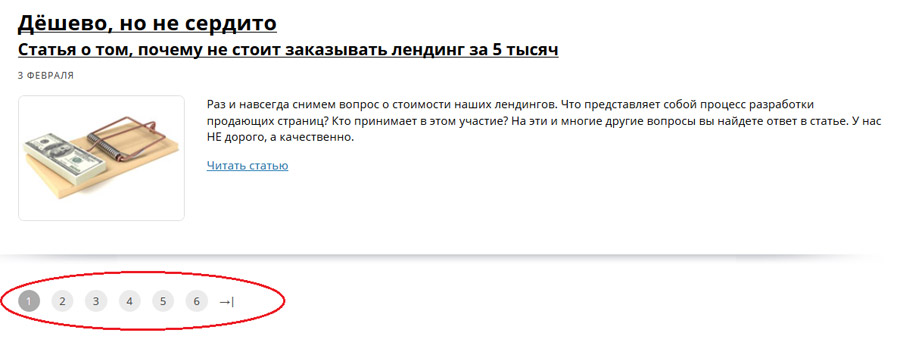
- Из-за страниц пагинации, когда в одном разделе несколько страниц.
Пример страниц пагинации. Они находятся под цифрами 1, 2, 3 и т. д. Такое можно встретить, например, в блогах, где много статей или в многостраничных каталогах. И чтобы бесконечно не скролить вниз, делается их разбивка на внутренние страницы по номерам:
Почему дублированный контент вредит сайту?
- Негативно влияет на продвижение в поисковой выдаче. Поисковые роботы отрицательно относятся к дублированному контенту и могут понизить позиции в выдаче из-за отсутствия уникальности, а следовательно, и полезности для клиента. Нет смысла читать одно и то же на разных страницах сайта.
- Может подменить истинно-релевантные страницы. Робот может выбрать для выдачи дублированную страницу, если посчитает ее содержание более релевантным запросу. При этом у дубля, как правило, показатели поведенческих факторов и/или ссылочной массы ниже, чем у той страницы, которую вы целенаправленно продвигаете. А это значит, что дубль будет показан на худших позициях.
- Ведет к потере естественных ссылок. Когда пользователь делает ссылку не на прототип, а на дубль.
- Способствует неправильному распределению внутреннего ссылочного веса. Дубли перетягивают на себя часть веса с продвигаемых страниц, что также препятствует продвижению в поисковиках.
Как проверить, есть у вас дубли или нет?
Чтобы узнать, есть у страниц сайта дубли или нет, существует несколько способов.
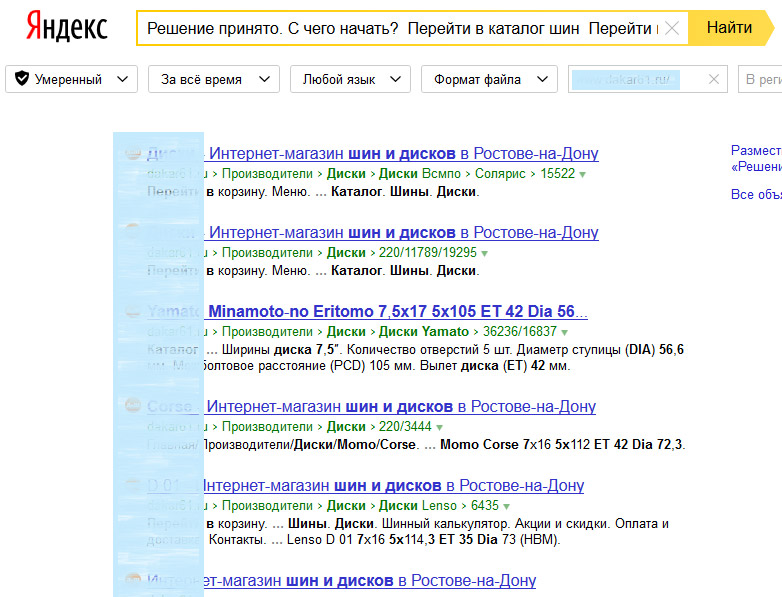
- Проверка через расширенный поиск (например, yandex.ru/advanced.html). Для этого просто вбиваете адрес сайта и фрагмент текста со страницы, контент которой надо проверить на дубли, в соответствующие поля формы и смотрите результат. Если в выдаче появилась только одна страница, то дублей нет. Если результатов больше, это говорит о том, что у страницы сайта все такие есть дубли, и с этим надо что-то делать.
На примере показано, что у страницы сайта нашлось несколько дублей через расширенный поиск Яндекс
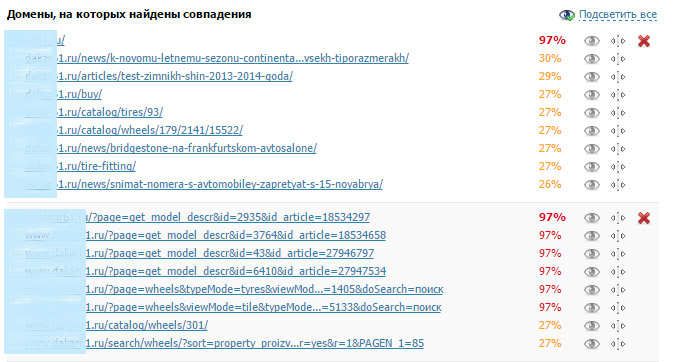
- Проверка через программы оценивания уникальности (например, «Text.ru»). Итоги проверки покажут вам, с какими сайтами и их внутренними страницами совпадает анализируемый текст и на сколько процентов.
На примере видно, с какими внутренними страницами и на сколько процентов совпадает контент анализируемой страницы. Анализ проводится через сайт text.ru:
Нашли дубли? Читаем, как их обезвредить:
- 301-й редирект. Этот способ считается самым надежным при избавлении от лишних дублей на вашем сайте. Суть метода заключается в переадресации поискового робота со страницы-дубля на основную. Таким образом, робот проскакивает дубль и работает только с нужной страницей сайта. Со временем, после настройки 301-ого редиректа, страницы дублей склеиваются и выпадают из индекса.
- Тег <link rel= "canonical">. Здесь мы указываем поисковой системе, какая страница у нас основная, предназначенная для индексации. Для этого на каждом дубле надо вписать специальный код для поискового робота <link rel="canonical" href="http://www.site.ru/original-page.html">, который будет содержать адрес основной страницы. Чтобы не делать подобные работы вручную, существуют специальные плагины.
- Disallow в robots.txt. Файл robots.txt – своеобразная инструкция для поискового робота, в которой указано, какие страницы нужно индексировать, а какие нет. Для запрета индексации и борьбы с дублями используется директива Disallow. Здесь, как и при настройке 301-го редиректа, важно правильно прописать запрет.
Как убрать дубли из индекса поисковых систем?
Что касается Яндекса, то он самостоятельно убирает дубли из индекса при правильной настройке файла robots.txt. А вот для Google надо прописывать правила во вкладке «Параметры URL» через Google Вебмастер.
Если у вас возникнут трудности с проверкой и устранением дублированного контента, вы всегда можете обратиться к нашим специалистам. Мы найдем все подозрительные элементы, настроим 301-й редирект, robots.txt, rel= "canonical", сделаем настройки в Google. В общем, проведем все работы, чтобы ваш сайт эффективно работал.









